The proven all-in-one platform to maximize ad revenue
Protect your ad revenue against invalid traffic and ad fraud

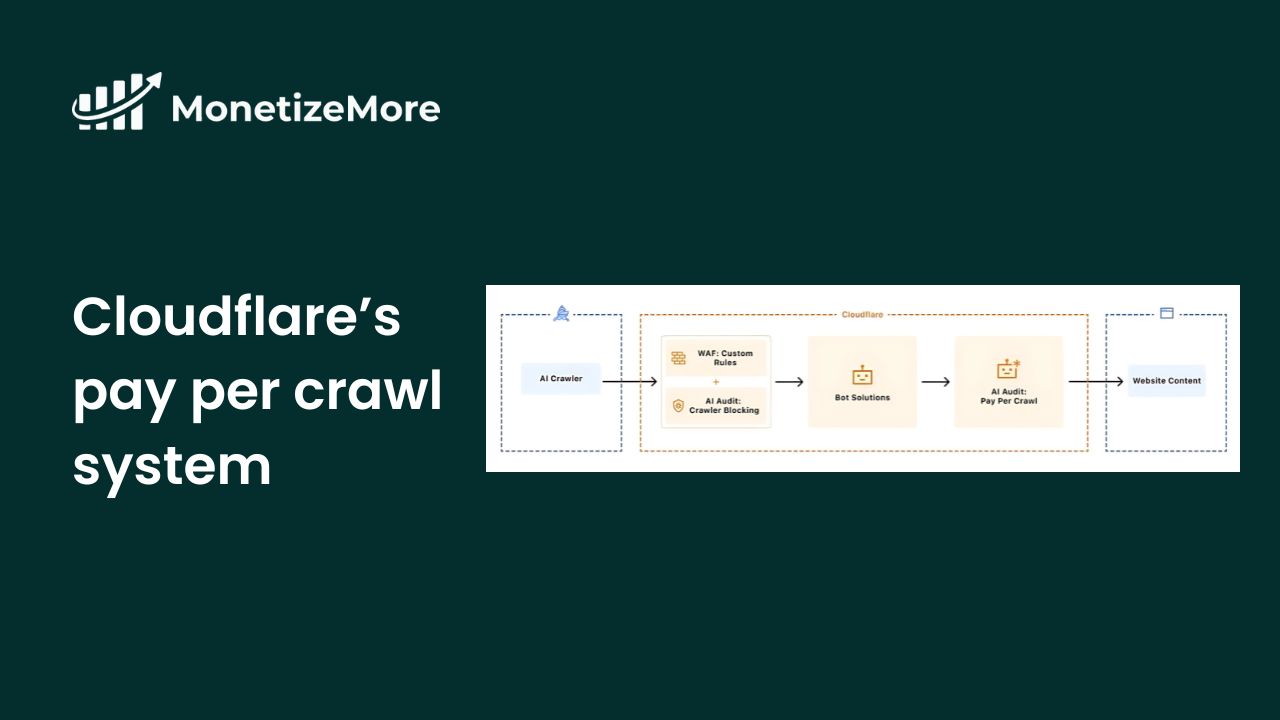
AI companies rely on scraping the open web for training data, but publishers have had only two choices: block crawlers (losing visibility) or allow free access (losing revenue).
Cloudflare’s Solution: A new Pay Per Crawl system that lets publishers:
402 Payment Required) for seamless integration.
 MonitizeMore")
| Feature | Technical Implementation | Publisher Control Levers |
|---|---|---|
| Pricing | Flat fee per request (e.g., $0.05) | Adjust by domain/page/crawler |
| Access Enforcement | HTTP 402 Payment Required + Robots.txt directives |
Throttle/block non-paying bots |
| Authentication | API key or cryptographic proof | Whitelist/blacklist AI vendors |
Training Data Costs Could Surge 30-60%: If top 10K publishers adopt fees (Perplexity AI internal modeling).
Model Quality Implications:
Current Practice: 85% of LLM training data comes from free web scraping (Stanford HAI, 2024).
Risk: Blocking by premium publishers (e.g., NYT, WSJ) could remove 18% of high-E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) content from training pools.
Vendor Response Likelihood:
Compliance Probable: Startups (Anthropic, Mistral) needing niche data → 80% adoption likelihood.
Resistance Expected: Google (indexing 130T+ pages) → may develop “free-tier” workarounds.
Scenario: If Pay Per Crawl Gains Critical Adoption (50%+ major publishers)
| Ranking Factor | Current AI SERPs | Post-Adoption Shift |
|---|---|---|
| Content Freshness | Crawled daily (free) | Delayed for non-payers |
| Source Authority | Links + domain age | Licensed content prioritized |
| Answer Depth | Surface-level synthesis | Paid sources yield richer context |
| Publisher Viability | Traffic cannibalization | Direct monetization → sustainability |
This isn’t a feature – it’s an ecosystem reset. Pay Per Crawl could shift $2B+ in value from AI companies to publishers by 2027, but only if:
- Top 1,000 publishers enforce fees (creating data scarcity leverage),
- Search/AI giants face regulatory pressure to comply (e.g., FTC “fair scraping” rules), and
- Infrastructure allies (AWS, Fastly) adopt compatible standards.
Invalid Traffic (IVT) drains an additional 15-30% of ad revenue (IAS, 2024).
 MonitizeMore")
✔ AI Scraping Protection – Complements Pay Per Crawl by filtering malicious bots.
✔ IVT Elimination – Stops fake clicks/impressions, stealing your ad revenue.
✔ One-Click Integration – Works alongside Cloudflare/Pay Per Crawl setups.
Publisher Case Study: TechNews blocked IVT + monetized AI crawlers → +22% net revenue in 90 days.
| Step | Tool | Outcome |
|---|---|---|
| 1. Charge AI crawlers | Cloudflare Pay Per Crawl | New revenue stream |
| 2. Block IVT & bad bots | MonetizeMore’s Traffic Cop | Protect existing ad earnings |
| 3. Audit traffic | Google Analytics + Traffic Cop | Full monetization transparency |
Why choose between AI money and ad money? Take both; Get started with Traffic Cop here.
 MonitizeMore")
With over ten years at the forefront of programmatic advertising, Aleesha Jacob is a renowned Ad-Tech expert, blending innovative strategies with cutting-edge technology. Her insights have reshaped programmatic advertising, leading to groundbreaking campaigns and 10X ROI increases for publishers and global brands. She believes in setting new standards in dynamic ad targeting and optimization.

10X your ad revenue with our award-winning solutions.



